Platform
VESTA is a timeline based annotation platform of multimedia content. It offers an integrated set of innovative computer tools for analyzing and annotating audio and video recordings. These tools allows to significantly accelerate, and in some cases, automate the analysis and annotation of your recordings. See below for more information on these tools.
As a web-based collaborative platform, your analysis and annotations can be shared among other researchers, thus increasing cooperation and opening the door to larger-scale multi-partner studies. VESTA results in considerable gains in productivity by significantly reducing analysis time while improving consistency.
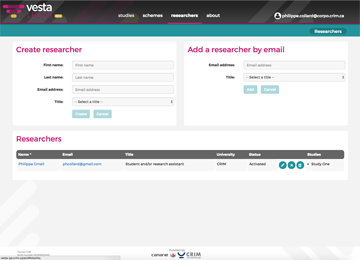
Build your team
Invite researchers and set their access rights
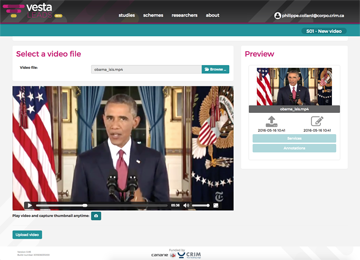
Manage your projects
Create studies and upload files
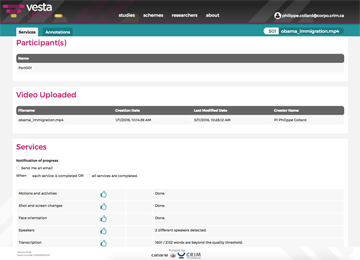
Start annotation services
Let our tools annotate your files automatically
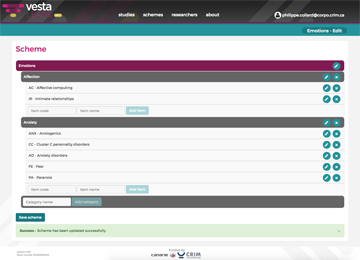
Design your own coding schemes
Use our graphical tool to build your schemes
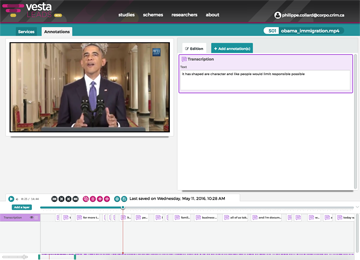
Work with annotations
Move, merge, split, add and update annotations
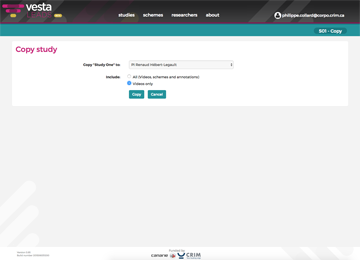
Share your projects
Give other teams access to your work and export it














